Don’t be fooled: data security requires global data lineage, not “local lineage”

October 29, 2024
•
1 min
|
Updated:
April 29, 2025
Securing data today requires the context provided by data lineage: where data came from, who interacted with it over time, which systems have used it, and more. But buyer beware: many vendors now claim to offer “data lineage” that only provides a tiny fraction of the context of true, global data lineage.
Why security teams demand more than content inspection
Security leaders increasingly demand “smarter” solutions for securing their data. They want to go beyond basic pattern-matching to identify sensitive information, which in data security is called “content inspection.”
In response, more vendors claim that they secure data by using both content inspection and “context” – such as information about where data came from, not just the text contained within it – as a better approach to securing information.
At Cyberhaven, we applaud this move, as we were one of the first to go beyond content inspection to assess data sensitivity and risk. We pioneered the Data Detection and Response (DDR) category, combining aspects of traditional data loss prevention (DLP) solutions with insider risk management (IRM) solutions and other best practices in data security.
Data lineage, specifically “global” data lineage, which covers the complete history of data, enables this context-based approach.
In this article, we’ll examine why context is helpful and necessary, how data lineage provides that context, and why security products with only “local data lineage” provide dangerously incomplete protection. In the end, we’ll give a handful of questions you can use to test whether the “lineage” a vendor provides is the kind of global data lineage that protects data and reduces risk.
Context: the missing piece for assessing data security risk
Changes in the way organizations work have made securing data harder than ever. The adoption of cloud computing, SaaS apps, hybrid work, bring-your-own-device (BYOD) policies, laptops, mobile devices, and more have introduced new variables into the risk equation for security leaders. Instead of having all sensitive information within the perimeter of a trusted network, data now resides in a constellation of public clouds, private clouds, and endpoint devices that span jurisdictions and geographies.
For decades, data security products have relied almost exclusively on content inspection to secure data. In simple terms, most forms of content inspection rely on pattern matching: numbers in the pattern of XXX-XX-XXXX probably signified US Social Security Numbers, numbers starting with known area codes were treated as phone numbers, text fields with “@” followed by “.com” were treated as emails, and so on. Depending on the patterns matched, the data could be classified as different kinds of “sensitive” information.
While pattern-matching was better than what came before, which was generally no security, there were some notable shortcomings. First, content inspection requires the content to be inspectable, which means it is unencrypted. However, in an age where encryption is increasingly the norm, traditional or “legacy” data security tools have become blind to encrypted data. Second, relying on pattern-matching alone generates an enormous amount of false positives, which continues to frustrate security teams.

To determine if an alert is a false positive, security analysts must look at the user’s behavior, whether the file has been tagged or labeled, how it got into the user’s hands, and more. In short, they are looking for more context – precisely the kind of context provided by data lineage.
How data lineage provides the context necessary to protect data
Data lineage is not merely a timeline or collection of snapshots in time. It’s a full-fidelity representation of the flow of data over time, showing who interacted with it, how they interacted with it, how the data changed, and which systems and machines were involved.
As data moves throughout your company, from person to person and application to application, it fragments and combines with other data. In Cyberhaven’s case, we calculate the lineage for every piece of data, starting with its origin through every step it takes.

In technical terms, this requires graph databases, which store the relationships between things. Yet even the leading off-the-shelf graph databases weren’t up to the task, so we had to create our own. (More on why that is below.)
Given the power of data lineage, it’s no surprise that more data security software providers are incorporating “lineage” and “context” into their marketing materials. Unfortunately, this creates some confusion among buyers, as the “lineage” they’re offering is only distantly similar to the kind of comprehensive context needed to protect data.
Seeing the whole picture vs. scattered fragments
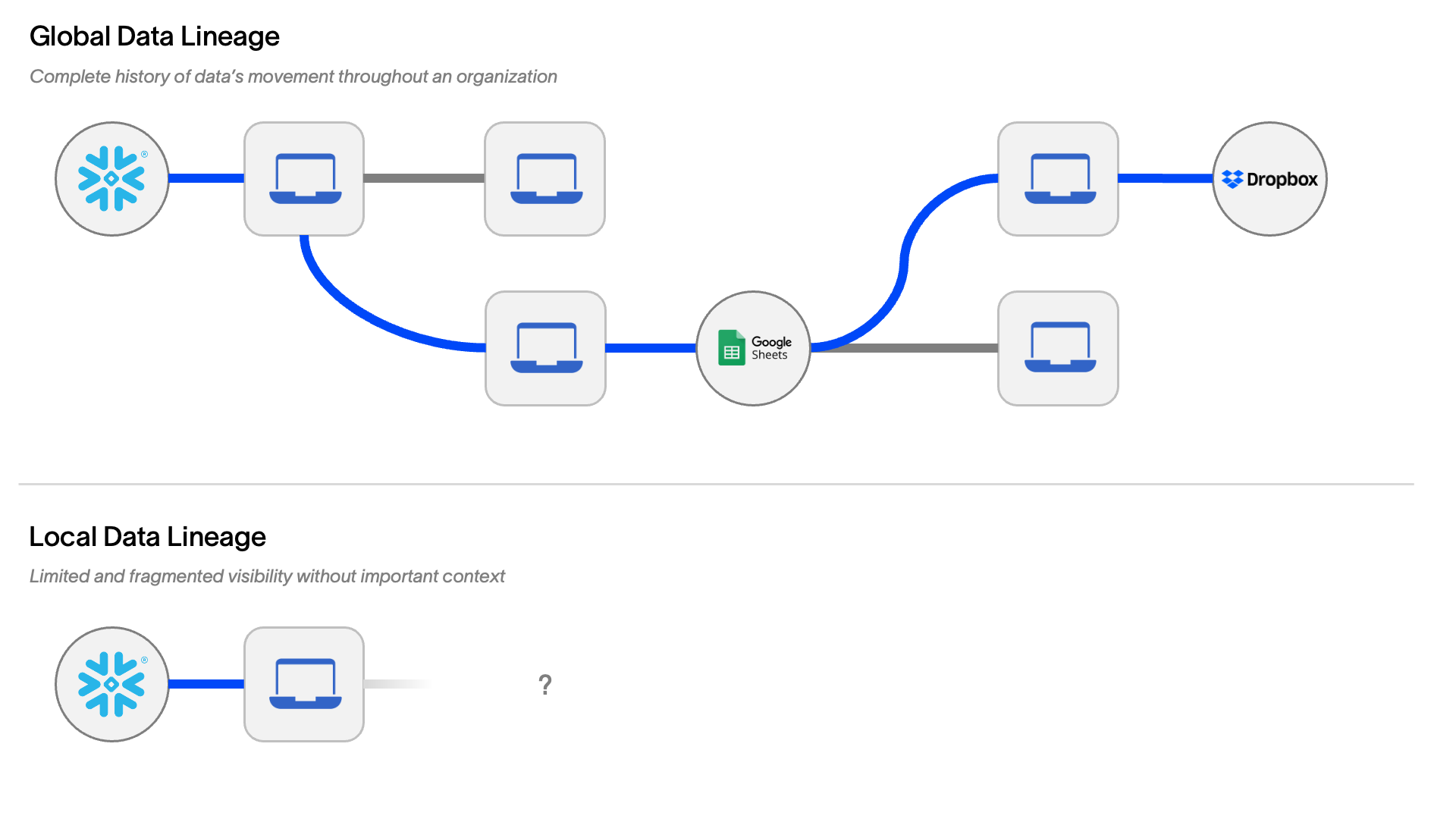
As with other kinds of context, scope matters. Here, it’s helpful to distinguish between two kinds of data lineage:
- Global data lineage: Sometimes called “true” data lineage, global data lineage traces the entire history of data across an entire organization. This reflects the natural and practical realities of how data is created, modified, and evolved in organizations: moving across endpoints, cloud, and between individuals over time. Global data lineage provides a complete view of data.
- Local data lineage: In contrast, local data lineage is limited to a specific person, cloud, or endpoint machine and considers only how that person or machine has interacted with the data. That means it’s blind to what might have happened before the data arrived and to what happens after it’s sent to another part of the organization. “Local lineage” is incomplete, so it provides only an incomplete view of data.
To understand how global data lineage provides significantly better protection, consider the journey a piece of data may take within an organization.
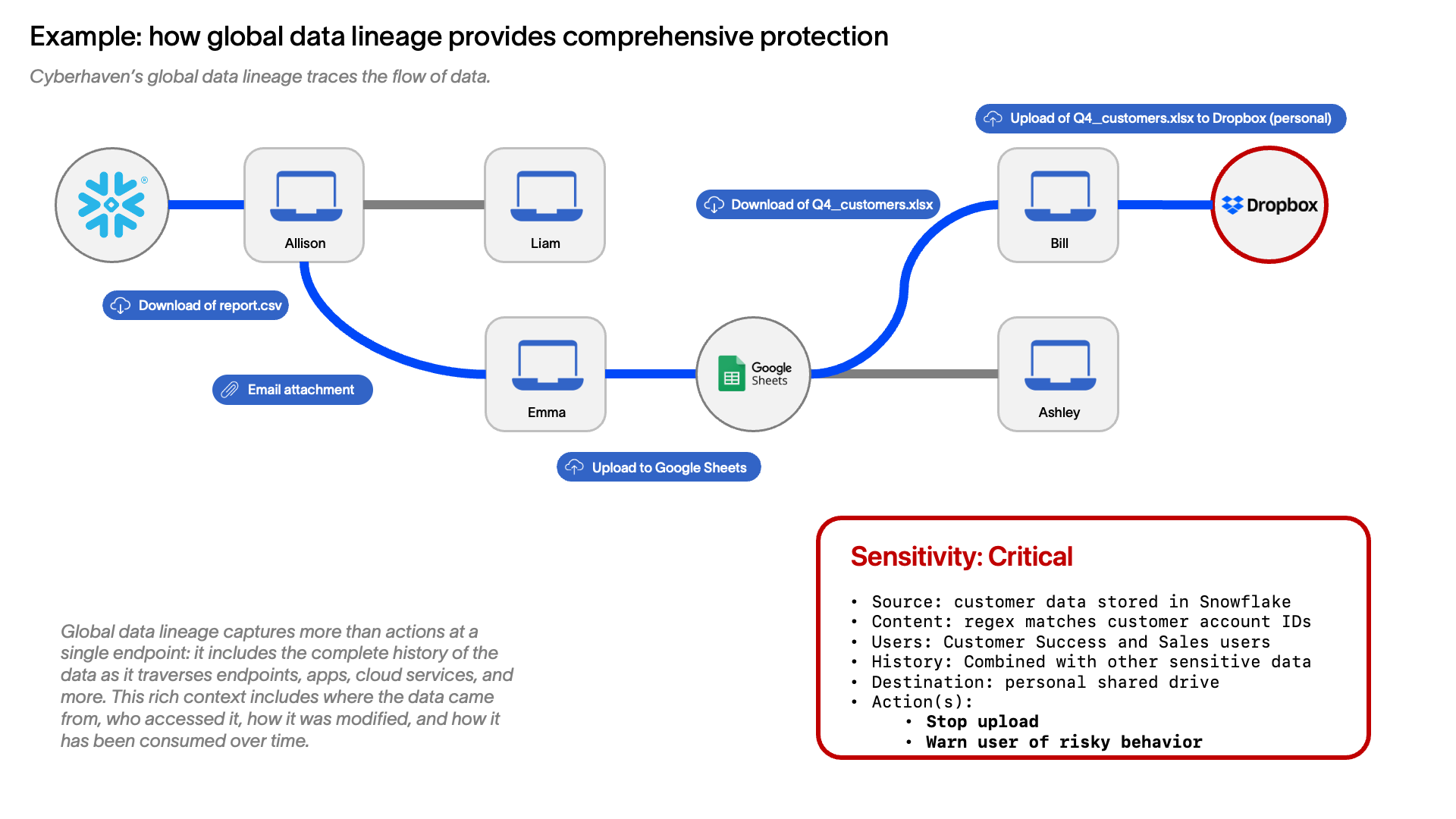
In the image below, a dataset containing customer data might be downloaded from Snowflake as a .csv file and sent as an email attachment to colleagues, one of whom uploads the spreadsheet to Google Sheets to analyze the data. The dataset is then available to anyone with access to that sheet, which could be many other employees if it’s stored in a shared folder or team drive. For example, Ashley might download the customer data for further analysis in Excel (because they are more familiar with it than Google Sheets) and to use it in planning for the next quarter. Another employee, Bill, might have a legitimate business interest in the data, as he works in sales and wants to understand which accounts are the most successful and, therefore, what kinds of customers are most likely to buy. Yet because Bill has also been interviewing with competitors, he has the idea to save a copy of the data to his personal Dropbox. Knowing which customers are the least happy might give him ideas for who to call when he starts his next job.
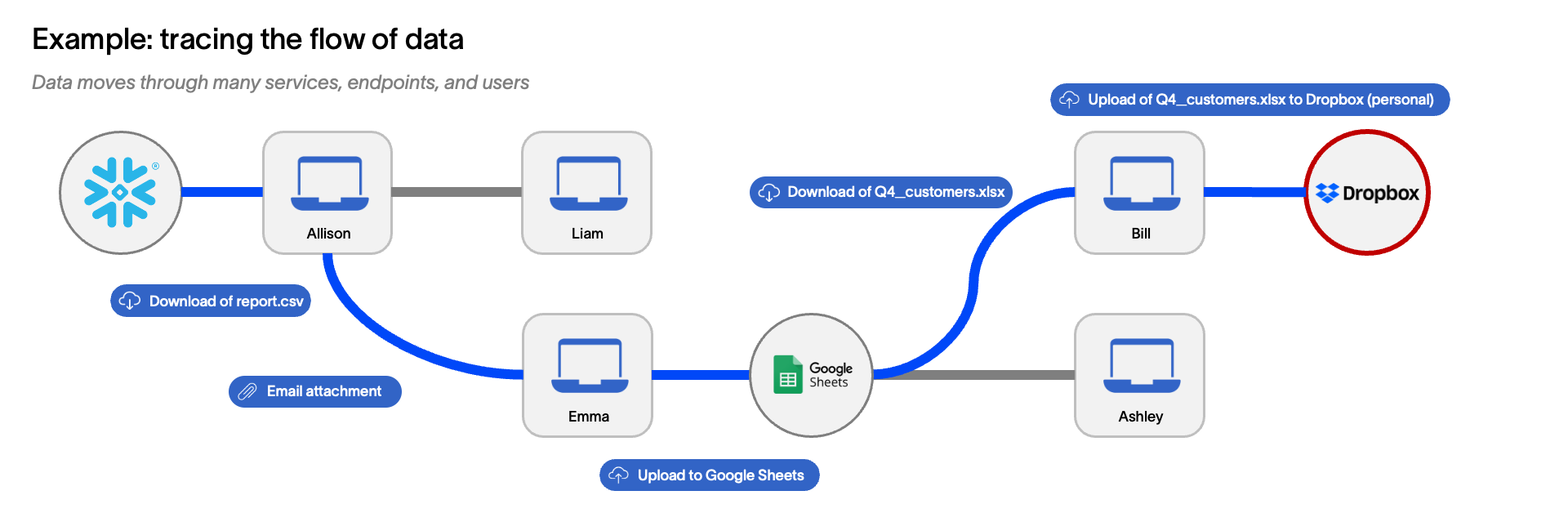
Such a data flow is very typical, even a bit simplistic, as is the behavior of the users. A single piece of data can easily traverse dozens of different data stores, devices, SaaS applications, and local applications at the endpoint. Think of these different steps as the “degrees of separation” or, more simply, the “hops” that a piece of data may take in its history. In our example, the original piece of customer data took four “hops” between the original data store and Bill’s laptop without any modification to the data. If it were modified along the way – such as by combining with other datasets or adding calculated fields to combine existing fields or comments – the number of hops between the original data and its current form could easily grow to 50, 100, or more, any one of which could significantly affect the sensitivity of the data. (Note: these increasingly high degrees of separation – which drive exponential increases in complexity – are also why Cyberhaven developed a proprietary graph database, as many off-the-shelf graph databases can only remain performant with a few degrees of separation.)
As an aside, this doesn’t even consider who accesses and modifies the information, taking into account their roles within the organization. (For more information, check out our recent blog on the convergence of DLP and IRM.)
So, how would two data security products, one with local data lineage and one with global data lineage, protect this data from exfiltration?
Local data lineage lacks sufficient context to protect data
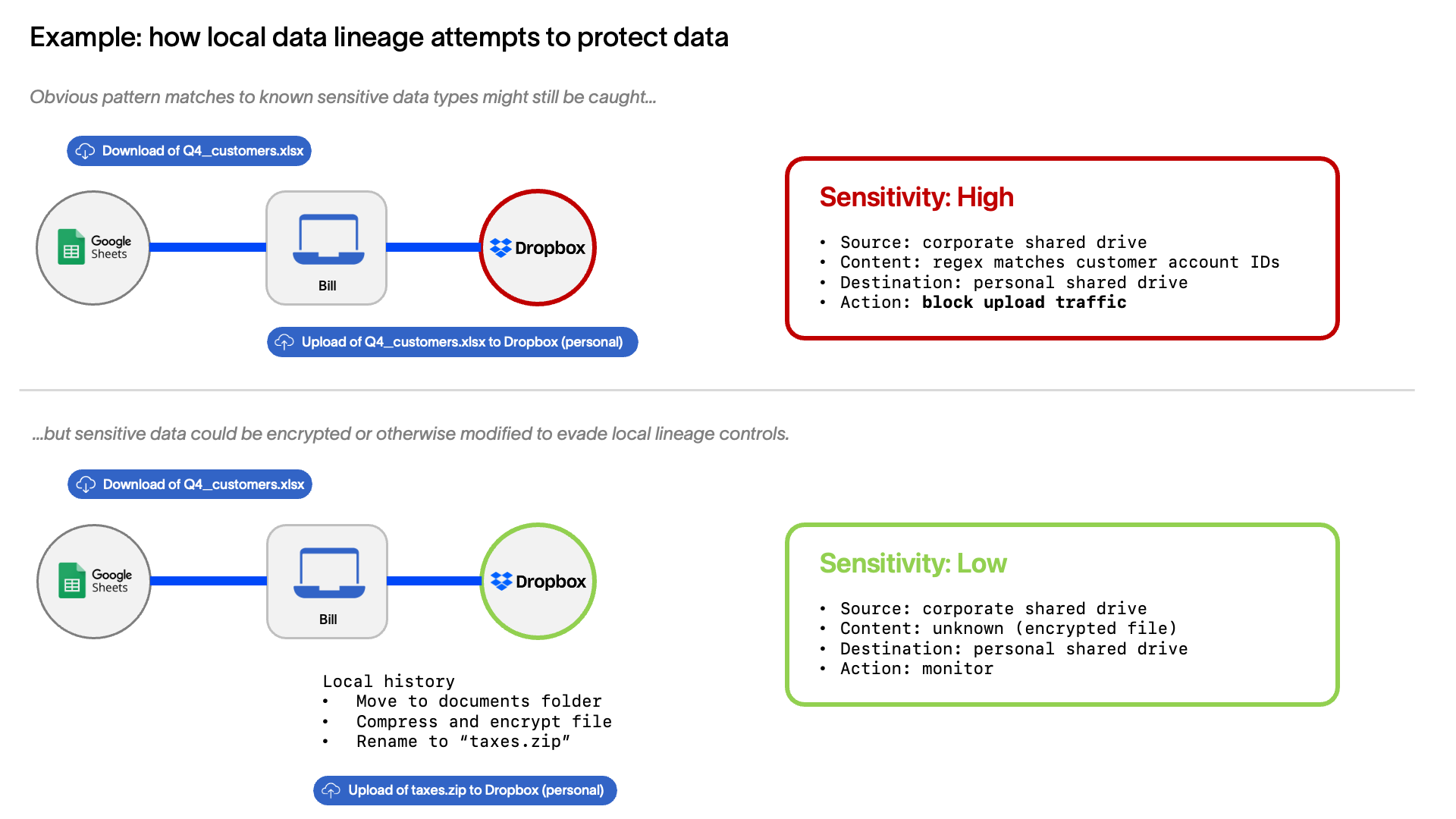
In the case of the product with local lineage, it would only see what happened at the endpoint. In our example, the endpoint agent on Bill’s laptop would see that:
- He downloaded a file from a corporate shared drive
- The file contained patterns matching regex rules in DLP policies, indicating that it’s sensitive data
- He attempted to upload the sensitive data to his personal Dropbox account
If extensively configured and maintained, it might also know something about the specific folder in the corporate drive from which the file came. If Bill took additional steps to obfuscate his data theft, such as compressing the file and renaming it, these actions might also be captured and provide incident investigators with more evidence of Bill’s violation of company policy. On the other hand, if the file were encrypted and stored in a folder without very precise sensitivity labels, the endpoint agent would be blind to the contents and potentially unable to see that Bill took sensitive data at all. Furthermore, many products offering local lineage only store the history for a limited timeframe, such as 30 or 60 days, so a savvy threat actor could wait to exfiltrate the data until prior history has been erased.
Global data lineage provides greater protection because it contains more context
In contrast to the narrow view provided by local data lineage, a data security product with global data lineage would see the entire history of the data, including across the dozens or hundreds of “hops” – degrees of separation – from the original sensitive data store, through employees that often handle sensitive data, right down to any steps Bill might have taken to hide his actions right before stealing the data. Not only does this give security teams a far richer and clearer timeline for incident investigations, but that vital context can help automatically stop exfiltration.
Furthermore, global data lineage is the more “future-proof” option. The world and workforce are quickly becoming more collaborative, which was accelerated by the disruptions of the COVID-19 pandemic and resulting work-from-home (WFH), hybrid work, and remote work arrangements that added to existing trends towards satellite offices, offshoring, and other forms of multinational collaboration. As these trends continue, the movement of data will only increase, which means that products limited to local data lineage will look at an increasingly smaller part of the overall picture and thus provide diminishingly effective protection.
Questions to distinguish global data lineage from local lineage
Here are some questions to help you understand whether a proposed solution using “lineage” is a true data lineage solution or a product with only partial coverage and a false sense of security.
- Can you trace the flow of data from an endpoint back to its source, whether that’s another endpoint, a SaaS application, etc.?
- Can you see how the data was accessed and modified and by whom before it reached a given endpoint?
- Does it allow for multi-dimensional exploration of the data? For example, can you analyze the types of information that people on a certain team, spanning multiple endpoints, typically interact with?
- Does it allow data to be classified based on who interacted with it over time before reaching a given endpoint device? Does it do this dynamically or based on rigid role-based classifications?
- Does it track data at a granular level that’s not contained within files? For example, information copied from Workday, sent to someone else via Slack, then copied from Slack and pasted into an email.
If you answered “Yes” to these questions, you’re probably looking at a true data lineage solution that provides the global coverage necessary to protect your data. If you answered “No” to some or all of the questions, you’re looking at an incomplete “local data lineage” product that might capture some local history on an endpoint but lacks the full context to identify and protect sensitive data accurately.
If you want to learn more about how data lineage can secure your data, click the button below to request a demo today.




.avif)
.avif)
